 Miklal serves publishers in the production of interlinear texts, and particularly in producing the contextual glosses—the English words that appear directly below each source language word. Our Print Interlinear Enabler Tool is a customizable software tool designed to help produce contextual glosses for an interlinear text of the Bible quickly, and so that the glosses make sense in terms of a given translation (KJV, NIV, ESV, etc.), without compromising accuracy with respect to the original language.
Miklal serves publishers in the production of interlinear texts, and particularly in producing the contextual glosses—the English words that appear directly below each source language word. Our Print Interlinear Enabler Tool is a customizable software tool designed to help produce contextual glosses for an interlinear text of the Bible quickly, and so that the glosses make sense in terms of a given translation (KJV, NIV, ESV, etc.), without compromising accuracy with respect to the original language.
The Print Interlinear Enabler is built for functionality and speed. Using large data sets and advanced algorithms, the software generates a best guess at the desired gloss for each word. The role of the human user is, then, simply to correct the algorithmic glosses. With the help of convenient displays that provide the most relevant data for a given word in a visually compact way, this process is informed and efficient.
Are you interested in producing a similar product using our Enabler Tool? Please contact us.
Print Interlinear Enabler Tool
The following video provides a demonstration of the Print Interlinear Enabler Tool and its functions.
Features of the Enabler Tool
The current version of the software was designed to produce a high-quality Hebrew-English Interlinear Bible for the English Standard Version (Crossway), so the following description of this tool will be in terms of its application for creating a Hebrew-English interlinear Old Testament.
The main frame of the Print Interlinear Enabler is a split frame, with the Interlinear Text Editor on the right and the Lexeme Information Table on the left. The Interlinear Text Editor occupies most of the screen real estate most of the time and is used for checking the algorithmic glosses; the Lexeme Information Table is useful for looking up various kinds of lexical information on the fly.
Interlinear Text Editor
The image below shows the Interlinear Text Editor, the right side of the main frame of the Print Interlinear Enabler.
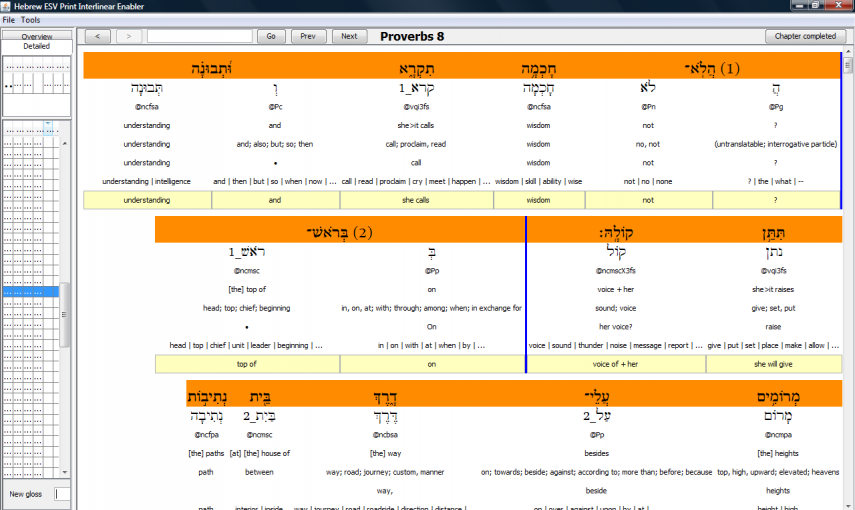
The goal of the Interlinear Text Editor is to display the Hebrew text along with several other pieces of information about the text in a manner that is conducive to the user’s being able to gloss each term with a minimum of effort. More specifically, the goals are twofold:
- To gloss each Hebrew word algorithmically in the same way that the user would most of the time, and
- To allow the user to gloss the vast majority of the Hebrew words without having to look at any other resources
This scrolling editor displays a chapter of the Hebrew text, along with various pieces of information about the Hebrew. Multiple rows present each of the following:
-

Interlinear Text Editor Closeup Hebrew text (orange)
- Hebrew lexeme(s)
- Morphology codes
- Contextual gloss
- Non-contextual gloss
- ESV translation
- Previous user glosses
- The user’s current gloss (yellow)
Initially the user’s gloss is determined algorithmically, but it is editable. The various rows line up in such a way that there is a column of information corresponding to each Hebrew word.
The user can edit the algorithmically-chosen gloss directly, but the user is also able to double-click on English words in the glosses/translations to choose any of the other glosses/translations listed as well. The user can double-click on a lexeme to jump to the Lexeme Information Table with an appropriate filter set so that only the entries for that lexeme are shown. This also automatically copies the lexeme to the clipboard so that he can look the word up in BDB or another resource in a Bible software application. Similarly, clicking on the verse number also copies the reference to the clipboard for interaction with another Bible software application.
Algorithmic Glosser
The application uses all of the data at its disposal to make its best guess at the gloss that the user will want. There are two major goals of the algorithmic glosser:
- To make the glosses conform to the publisher’s standards of consistency
- To get the gloss precisely as the user would choose it in the majority of cases
Perfection is impossible, but a variety of techniques are used to predict how the user himself would choose to gloss the Hebrew lexeme. This involves making use of all of the information presented to the user concerning the lexeme each time it has appeared in the canon, dissecting how the user has glossed it in the past, and on these bases predicting how he will gloss it in the present verse.
Lexeme Information Table
The image below shows a detail of the Lexeme Information Table.
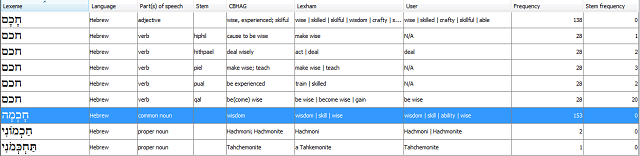
The Lexeme Information Table presents the relationships between Hebrew lexemes and their English equivalents in aggregate form. The table includes the following columns:
- Hebrew lexeme
- Part(s) of speech
- Non-contextual gloss
- Contextual glosses
- User glosses
- Lexeme frequency
The user can filter and sort it by any and all columns. If the user double-clicks on any row, the Detailed Lexeme Information Table for that lexeme is presented.
Detailed Lexeme Information Table
The Detailed Lexeme Information Table is shown below.
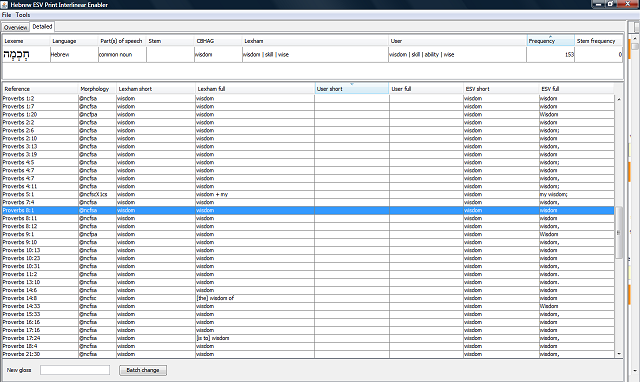
The Detailed Lexeme Information Table presents information for each occurrence of a particular lexeme throughout the Old Testament:
- Reference
- Morphology
- Contextual gloss
- User gloss
- ESV translation
And the basic info:
- Hebrew lexeme
- Part(s) of speech
- Non-contextual gloss
- Contextual glosses
- User glosses
- Lexeme frequency
This table also provides the ability to do batch editing of glosses for all occurrences of a lexeme.
More Information
The following slideshow gives an overview of the Print Interlinear Enabler Tool developed for Crossway (ESV), highlighting some of the challenges that had to be overcome along the way as well as the positive results that the Enabler Tool produced, in terms of both quality and speed of glossing every word in the Hebrew Bible. The slides are based on a paper given by Drayton Benner at the BibleTech Conference 2013. (Download full paper)